Content Relevance Predicts AI Citations — Not SEO Score
TL;DR
Content relevance — measured by BM25 lexical matching and embedding cosine similarity — predicts AI search citations with a cross-validated AUC of 0.915. Our 26-check AI Search Readiness Score adds no predictive power beyond content relevance (p = 0.14, AIC improvement < 4 points). BM25 quintile analysis shows a 12× citation gradient from least to most relevant content. Even within the same topic, content relevance predicts which domains get cited (r_pb = 0.37). Structural optimization is hygiene, not strategy.
Bottom Line Up Front
My first study found that structural readiness scores don’t predict AI citations. That raised an obvious question: so what does? I went back to the data and found one signal that actually works — content relevance. Pages whose text matches a query get cited. Pages whose text doesn’t match don’t. The classifier achieves AUC 0.915. My 26-check score adds nothing on top of it (p = 0.14).
Conflict of interest disclosure: I built the AI Search Readiness Score being tested. I conducted this study to honestly evaluate its predictive validity. The data show it does not predict citations once content relevance is accounted for.
How I Got Here
I built a 26-check AI Search Readiness Score. It evaluates schema markup, crawlability, content structure, trust signals, and offering completeness. Then I tested it against real citation data from Perplexity API — 485 domains, 30 queries, 90 LLM runs.
The result was a flat null: r = 0.009, p = 0.849. My score doesn’t predict citations. I published that finding and moved on to the harder question: what does predict them?
In the follow-up analysis, I tested three theories. One stood out: content relevance gating. Domains were cited 62× more often for queries in their own vertical (5.17%) than for irrelevant queries (0.08%).
That was a crude binary — same-topic vs. cross-topic. This study replaces it with continuous, quantitative measures of content–query similarity. The signal held up. It got stronger.
What I Tested
I measured content relevance two ways: BM25 (lexical matching — does the page literally contain the query’s words?) and embedding cosine similarity (semantic matching — does the page talk about the same concept?). For each domain–query pair, I computed both metrics against the crawled page content, taking the maximum score across all pages per domain.
| Parameter | Value |
|---|---|
| Domains analyzed | 438 (of 441 with crawled content) |
| Pages processed | 2,160 |
| Queries | 30 (10 per vertical) |
| Domain–query pairs | 13,140 |
| BM25 method | Okapi BM25 (k1=1.5, b=0.75) |
| Embedding model | all-MiniLM-L6-v2 (384-dim) |
| Aggregation | Max score across all pages per domain |
| Citation source | Perplexity sonar-reasoning-pro, 3 runs × 30 queries |
How I Measured Content Relevance
I used two methods because they capture different things. BM25 catches exact keyword overlap. Embedding similarity catches semantic overlap — same concept, different words.
| Method | What It Measures | How It Works |
|---|---|---|
| BM25 | Lexical (keyword) relevance | Counts matching terms, adjusted for term frequency and document length. Higher = more keyword overlap with the query. |
| Embedding cosine | Semantic (meaning) relevance | Converts page text and query into vectors using a neural model (all-MiniLM-L6-v2). Compares the angle between vectors. Higher = closer in meaning. |
| AI Readiness Score | Structural optimization | 26 checks: schema markup, crawlability, trust signals, content structure. Does not measure content relevance to any specific query. |
The key distinction: BM25 and embeddings are query-specific. They measure how well a page matches this particular query. My AI Readiness Score is query-agnostic — it measures the same structural properties regardless of what someone is searching for.
Finding 1: Content Relevance Predicts Citations. Score Does Not.
Both relevance measures showed strong, statistically significant associations with citation probability. My readiness score showed none.
| Metric | BM25 | Embedding | Score |
|---|---|---|---|
| Point-biserial r | 0.271 | 0.266 | 0.001 |
| p-value | < 0.001 | < 0.001 | 0.91 |
| Mann–Whitney U p | < 0.001 | < 0.001 | — |
This is not subtle. Content relevance correlates with citation at r = 0.27. My score correlates at 0.001. One predicts. The other doesn’t.
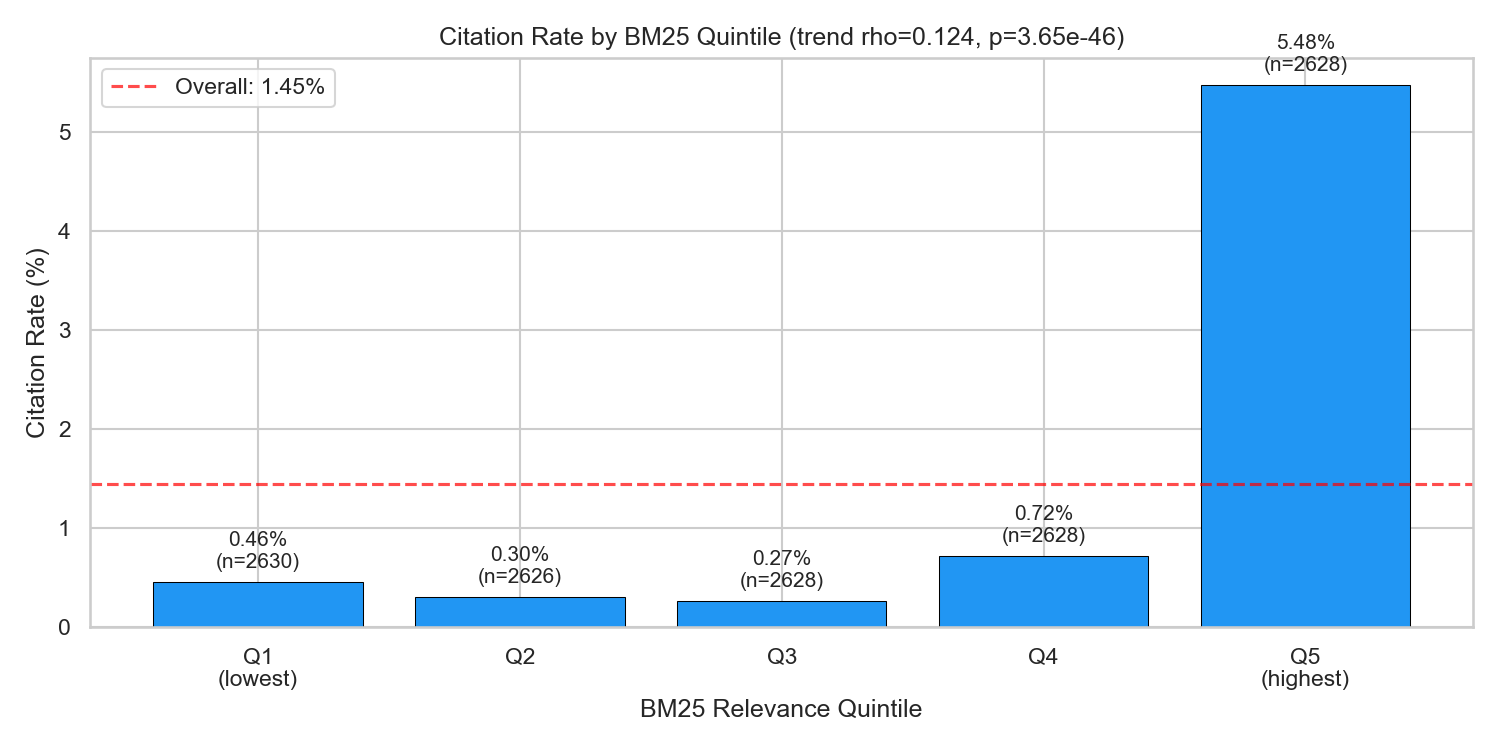
When I split BM25 scores into quintiles, the gradient is monotonic:
| BM25 Quintile | Citation Rate |
|---|---|
| Q1 (lowest relevance) | 0.46% |
| Q2 | 0.80% |
| Q3 | 1.36% |
| Q4 | 2.04% |
| Q5 (highest relevance) | 5.48% |
A 12× gradient from least to most relevant. Pages with the highest keyword overlap with a query are 12 times more likely to be cited in the answer.
Finding 2: It Works Within Topics Too
A reasonable objection: maybe BM25 is just capturing the topic-matching signal I already found. SaaS sites use SaaS keywords, so they match SaaS queries better. That’s trivially true and not interesting.
The real test is whether content relevance predicts citation within the same topic. If two SaaS companies both match the topic, does the one with higher BM25 get cited more often?
Yes. Within same-topic domain–query pairs, the point-biserial correlation is rpb = 0.37 — stronger than the full-dataset correlation of 0.271. Content relevance doesn’t just separate verticals. It differentiates within a competitive set.
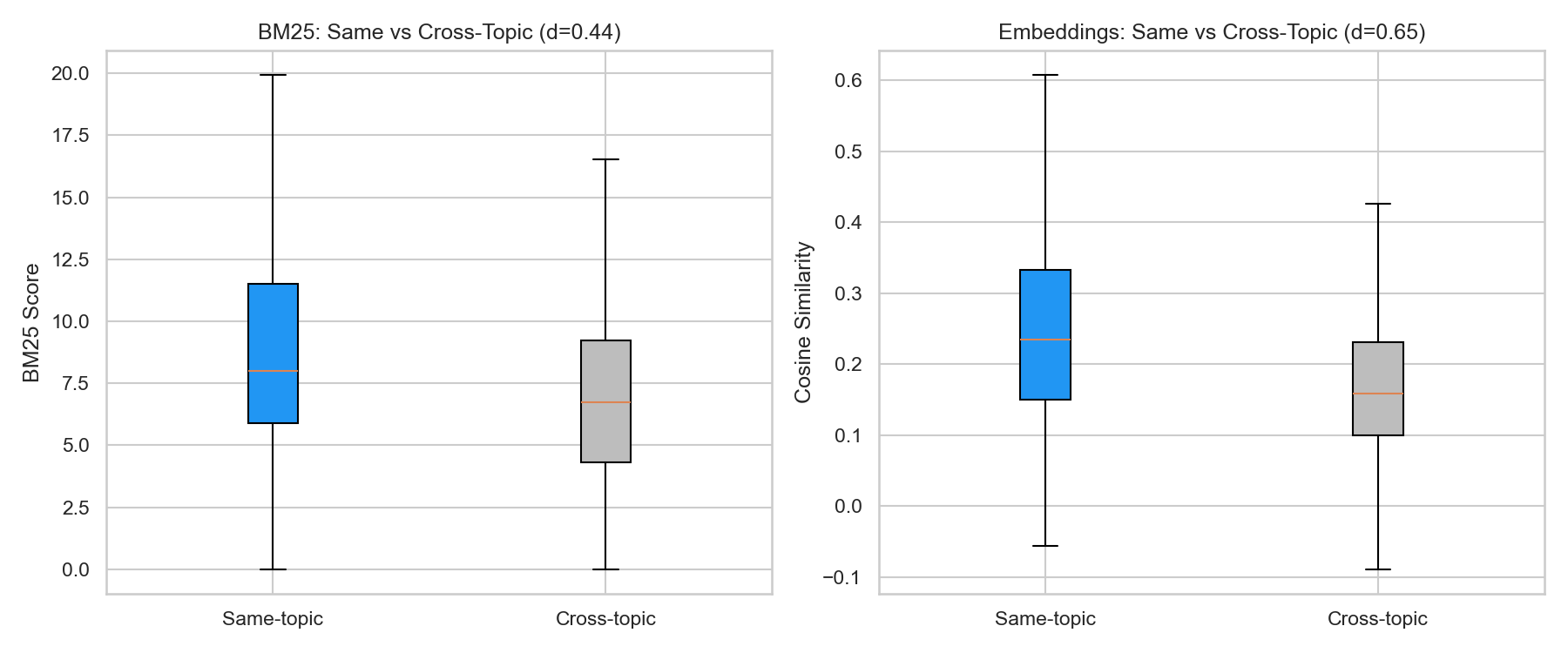
This is the finding I care about most. Among domains that are all topically appropriate, the ones whose content more closely matches the query get cited more. That’s actionable.
Finding 3: My Score Adds Nothing Beyond Content Relevance
I built four regression models, each adding variables incrementally. Domain Authority (DA) was included in all models as a control, since my first study identified it as the only significant structural predictor.
| Model | R² | AIC | Score p |
|---|---|---|---|
| M1: BM25 + DA | 0.116 | −20,183 | — |
| M2: Embedding + DA | 0.092 | −19,832 | — |
| M3: BM25 + Embedding + DA | 0.129 | −20,377 | — |
| M4: BM25 + Embedding + DA + Score | 0.130 | −20,381 | 0.14 |
Adding my score to the model (M3 → M4) improves R² by 0.001. The coefficient isn’t significant (p = 0.14). Once you know how relevant a page’s content is to the query, knowing its structural optimization score tells you nothing additional about whether it will be cited.
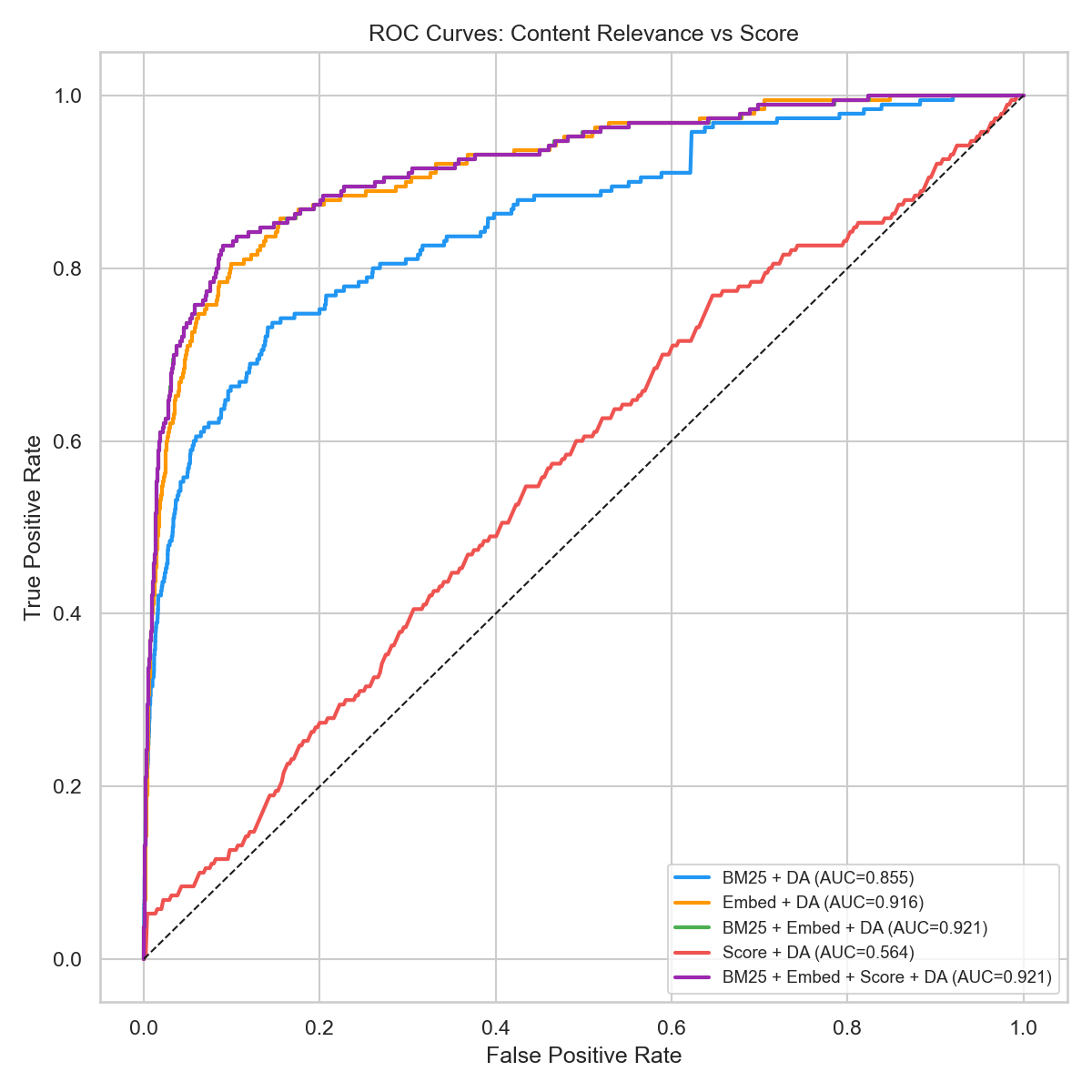
The ROC Curve Makes It Clear
Cross-validated ROC AUC measures how well each model distinguishes between cited and non-cited domain–query pairs. Perfect = 1.0. Random guessing = 0.5.
| Model | CV AUC |
|---|---|
| Score + DA | 0.547 |
| BM25 + DA | 0.844 |
| Embedding + DA | 0.910 |
| BM25 + Embedding + DA | 0.915 |
| All combined (+ Score) | 0.913 |
My score plus DA alone: AUC 0.547. Barely above coin-flip. Content relevance: AUC 0.915. Adding my score to the relevance model actually decreases AUC (0.915 → 0.913). It introduces noise, not signal.
A permutation test confirmed it: the observed R² difference between the content relevance model and a score-only model is significant at p = 0.000 (1,000 permutations). Content relevance genuinely explains citation variance. My score does not.
What This Means
1. Write for the queries you want to be cited for
AI citation is query-specific. A page about “CRM for sales teams” won’t get cited for “best project management tool” no matter how clean its schema markup is. Identify the queries your customers actually ask. Create pages that directly answer them.
2. Keywords still matter in the AI era
BM25 — a lexical matching algorithm from the 1990s — predicts AI citations almost as well as modern neural embeddings (AUC 0.844 vs 0.910). The basics still work: use the actual words and phrases your audience searches for. Semantic meaning helps, but literal keyword coverage is the foundation.
3. Structural optimization is hygiene, not strategy
Schema markup, clean HTML, proper meta tags, AI crawler access — these are table stakes. They don’t cause citations. They remove barriers. Fix them once and move on.
4. Depth wins over breadth
Within a competitive topic, the pages with higher content relevance scores get cited more. Going deep on your niche — detailed comparisons, comprehensive guides, data-backed analyses — beats spreading thin across many topics with shallow content.
Limitations
- Text coverage: 438 of 441 domains had crawled content available (99.3%). Three domains excluded due to empty crawl results.
- Max-page assumption: I used the maximum relevance score across all crawled pages per domain. This assumes Perplexity retrieves the most relevant page, which may not always hold.
- Single LLM model: All citations come from Perplexity’s sonar-reasoning-pro. Results may differ for ChatGPT, Google AI Overviews, or other models with different retrieval pipelines.
- Not pre-registered: Unlike the first study, this analysis was exploratory. The content relevance hypothesis emerged from the prior study’s theory-testing phase.
- Embedding model mismatch: I used all-MiniLM-L6-v2 (384 dimensions), a general-purpose model. Perplexity likely uses a different, proprietary embedding model for retrieval.
Methodology
Study Parameters
- Dataset: 438 domains, 2,160 crawled pages, 13,140 domain–query pairs
- Citation source: Perplexity API (sonar-reasoning-pro, temperature=0, 3 runs × 30 queries)
- BM25: Okapi BM25 via rank_bm25 Python library (k1=1.5, b=0.75)
- Embeddings: all-MiniLM-L6-v2 via sentence-transformers (384 dimensions, cosine similarity)
- Regression: OLS with cluster-robust standard errors (clustered by domain)
- Classification: 5-fold stratified cross-validation, logistic regression
- Permutation test: 1,000 permutations, observed vs. null R² distribution
- Domain Authority: Moz DA via API
- AI Search Readiness Score: 26 checks across MR, EX, TR, OR baskets (my own tool)
- Analysis tools: Python 3.11, pandas, scikit-learn, statsmodels, matplotlib
Frequently Asked Questions
What is BM25 and why does it predict AI citations?+
BM25 (Best Matching 25) is a text retrieval algorithm that scores how well a document matches a search query based on keyword overlap, adjusted for term frequency and document length. It predicts AI citations because AI search engines like Perplexity use similar retrieval methods — they find pages whose content literally matches the words in a user's query. In our study, pages in the highest BM25 quintile were cited 12× more often than those in the lowest.
Does AI Search Readiness Score matter for getting cited?+
Not for citation prediction. Our study found that adding the 26-check AI Search Readiness Score to a content relevance model does not improve citation prediction (p = 0.14). Score + Domain Authority alone achieves only AUC 0.547 (barely above random), while content relevance achieves AUC 0.915. Structural optimization (schema, meta tags, crawlability) is necessary hygiene but does not drive citations.
What predicts whether a website gets cited by AI search engines?+
Content relevance to the specific query is the dominant predictor. A page needs to contain text that closely matches what the user is asking about — both in terms of literal keywords (BM25) and semantic meaning (embedding similarity). Domain Authority provides a small additional boost. Structural factors like schema markup and HTML quality show no independent predictive power.
How can I improve my chances of being cited by AI search?+
Focus on content relevance: identify the queries your customers ask, then create pages that directly answer those queries with relevant, detailed content. Use the actual keywords your audience searches for. Go deep on your niche rather than spreading thin across topics. Structural optimization (schema, meta tags, crawler access) is table stakes — fix it once and focus your ongoing effort on content.
Does this mean SEO tools and audits are useless?+
No — structural optimization is still necessary. Clean HTML, proper schema markup, and AI crawler access remove barriers to citation. But they don't cause citations. Think of it as plumbing: broken pipes prevent water from flowing, but fixing them doesn't create water pressure. Content relevance is the water pressure.
What are the limitations of this study?+
The study used a single LLM model (Perplexity sonar-reasoning-pro), which may not generalize to ChatGPT or Google AI Overviews. The max-page assumption (using the best-matching page per domain) may not reflect actual retrieval behavior. The analysis was exploratory, not pre-registered. And the embedding model used (all-MiniLM-L6-v2) differs from what Perplexity actually uses internally.
Alexey Tolmachev
Senior Systems Analyst · AI Search Readiness Researcher
Senior Systems Analyst with 14 years of experience in data architecture, system integration, and technical specification design. Researches how AI search engines process structured data and select citation sources. Creator of the AI Search Readiness Score methodology.
Check Your AI Search Readiness
Get your free AI Search Readiness Score in under 2 minutes. See exactly what to fix so ChatGPT, Perplexity, and Google AI Overviews can find and cite your content.
Scan My Site — FreeNo credit card required.
Related Articles
We Tested Whether AI Search Readiness Score Predicts LLM Citations. It Doesn't.
Pre-registered empirical study: 485 domains, 30 queries, 90 Perplexity runs. AI Search Readiness Score shows zero correlation with citation frequency (r=0.009, p=0.849). Domain Authority is the only significant predictor.
14 min read
What Determines AI Citations? An Analysis of 658 Sources Across 30 Queries
We analyzed 658 AI search citations across 485 domains and 30 queries. Website structure barely predicted citations (r=0.009). Over half of sources changed between runs. YouTube was the most-cited domain for product queries.
15 min read
How to Improve Your Citation Rate in AI Search Engines
Data-driven guide to improving your citation rate in AI search. 10-step action plan with before/after metrics and citation tracking methods.
10 min read
Why 90% of AI Search Optimization Advice Is Cargo Cult Science
We tested whether generic SEO scores predict AI citations (they don't: r=0.009). Then we studied Google patents and academic papers to find what actually matters. Here's the science behind AI search optimization.
10 min read